2023年7月11日,百川智能正式发布参数量130亿的通用大语言模型Baichuan-13B-Base、对话模型Baichuan-13B-Chat及其INT4/INT8两个量化版本。
未来,大模型生态开源闭源并存已经是不争的事实,如同iOS与安卓。
目前,以GPT-4为代表的超大参数量闭源模型和100亿-200亿参数量开源模型,是大模型生态链中两个最佳实践。
GPT-4固然能力强大,但闭源会要求企业访问公网以及难以定制化适配,使用场景受限。而开源能够使企业轻松地借助专有数据进行微调和私有化部署,进而促进百行千业的良性发展生态。
Baichuan-13B中英文大模型集高性能、完全开源、免费可商用等诸多优势于一身,是目前所有33B以下尺寸开源模型中效果最好的可商用大语言模型。

内容创作

语言理解
多轮回答
在国外已建立起闭源及开源大模型完整生态的背景下,弥补了国内高品质开源商业模型的不足,对助力中国大模型产业发展和技术进步都具有重要意义。
这是百川智能发布的第二款通用大语言模型,而在前不久的6月15日,百川智能就已经推出了首款70亿参数量的中英文语言模型Baichuan-7B,并一举拿下多个世界权威Benchmark榜单同量级测试榜首。
开源地址
Hugging Face
预训练模型:
对话模型:
Github
Baichuan-13B:
Model Scope
预训练模型:
对话模型:
最强中英文百亿参数量开源模型
预训练模型「底座」因其灵活的可定制性,适合具有一定开发能力的开发者和企业产品参数的英文产品参数的英文,而普通用户则更关注具有对话功能的对齐模型。
因此百川智能在发布预训练模型Baichuan-13B-Base的同时还发布了其对话模型Baichuan-13B-Chat,Baichuan-13B-Chat部署简单、开箱即用,极大降低了开发者的体验成本。
相比此前发布的Baichuan-7B,Baichuan-13B在1.4万亿token数据集上训练,超过LLaMA-13B 40%,是当前开源13B尺寸下训练数据量最大的模型。
在语言模型中,上下文窗口长度对于理解和生成与特定上下文相关的文本至关重要。
Baichuan-13B上下文窗口长度为4096,不同于Baichuan-7B的RoPE编码方式,Baichuan-13B使用了ALiBi位置编码技术,能够处理长上下文窗口,甚至可以推断超出训练期间读取数据的上下文长度,从而能够更好的捕捉文本中上下文的相关性,做出更准确的预测或生成。
作为一款中英文双语大模型,Baichuan-13B采用了相对平衡的中英文语料配比和多语言对齐语料,从而在中英两种语言上表现均很优异。
在同等参数量的开源模型中堪称实力担当,能更好满足商业化场景需求。
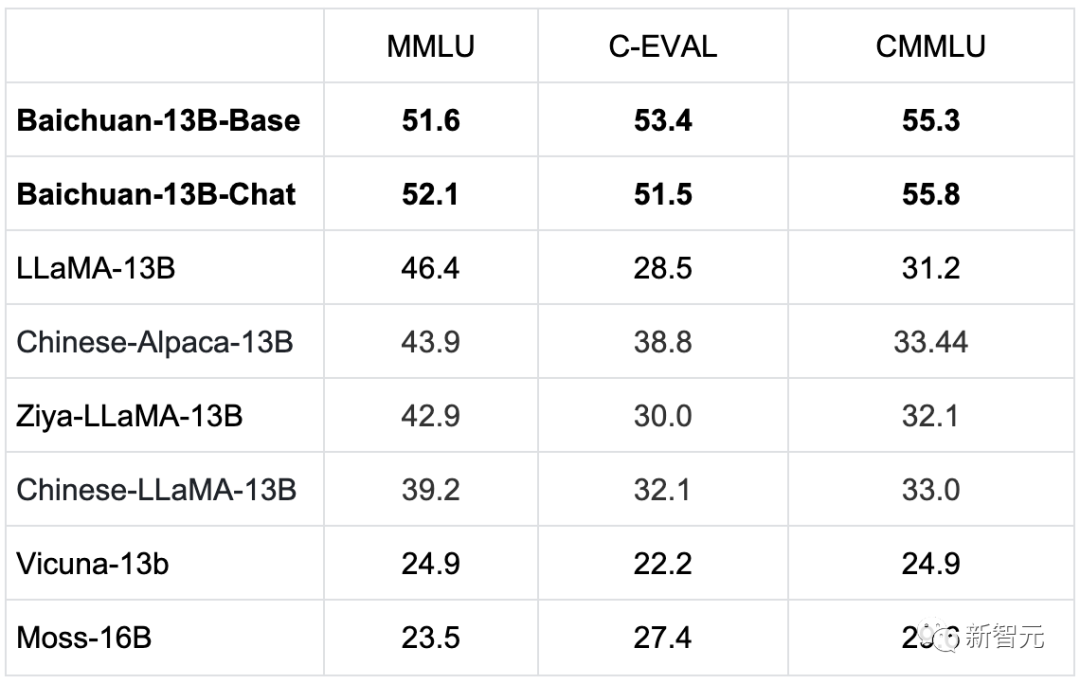
主流百亿参数开源模型benchmark成绩
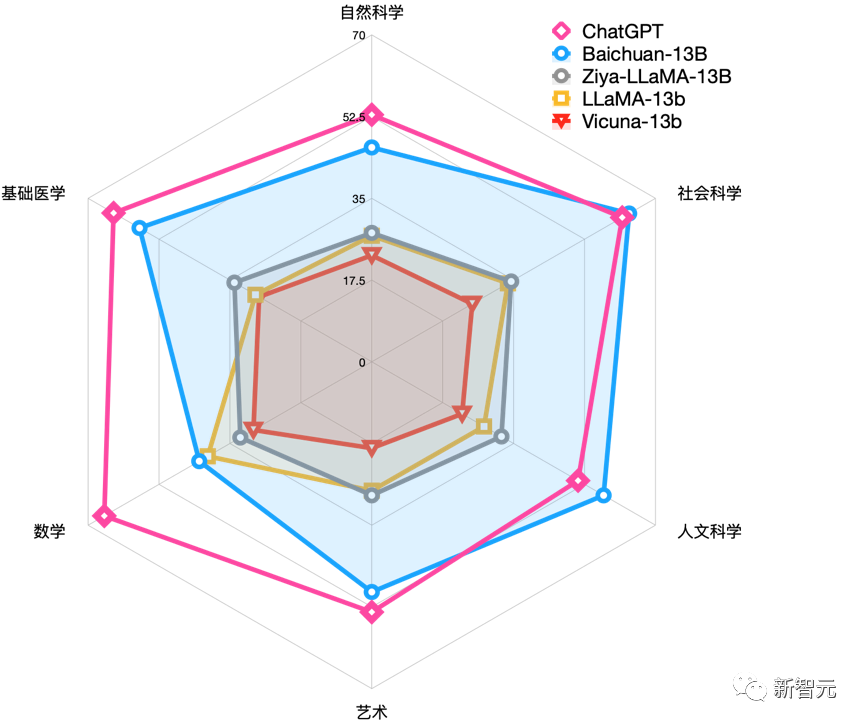
中文领域,在权威评测C-EVAL中,Baichuan-13B性能一骑绝尘,在自然科学、医学、艺术、数学等领域大幅领先LLaMA-13B、Vicuna-13B等同尺寸的大语言模型,在社会科学、人文科学等领域甚至超越了ChatGPT。
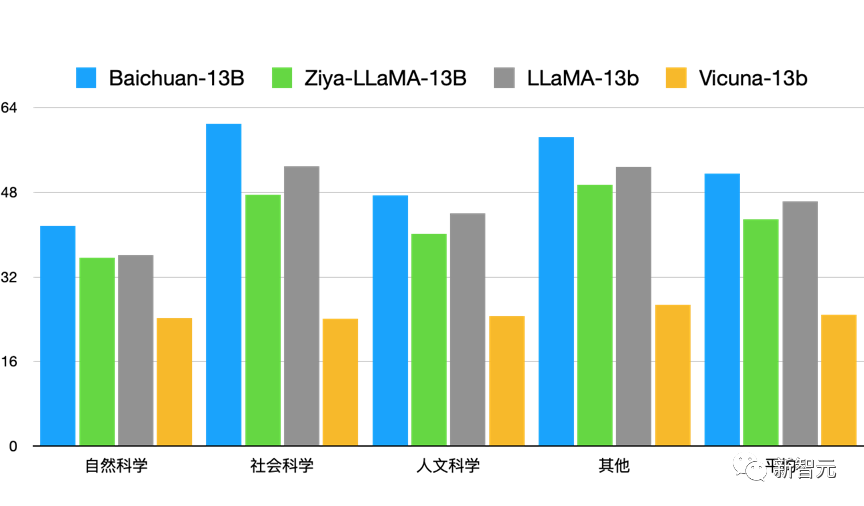
英文领域,其表现同样优秀,在英文最权威的榜单MMLU上,Baichuan-13B超过了所有同尺寸开源模型,并且在各个维度都具有显著优势。
必须要说的是,有些模型为了能在评测中取得更好的成绩,会在基座模型和对话模型上引入较多针对benchmark的优化。
此举虽然可以在榜单上获取更高的分数,但是没有本质地提升模型的基础能力,并且在下游任务中易产生回复长度短、质量低的问题,造成高分低能的现象。
百川智能的Baichuan-13B-Base和Baichuan-13B-Chat未针对任何benchmark测试进行专项优化,保证了模型的纯净度,具有更高的效能和可定制性。
亟待建立中国的开源大模型生态
众所周知,大模型的训练成本极高,在海量算力的成本压力下,OpenAI和谷歌都选择了闭源来保证自家大模型的优势地位。
但是从计算机科学与人工智能的发展历程来看,开源始终对软件技术乃至IT技术发展有着巨大的推动作用。
大模型时代,Meta率先走上了开源的道路,LLaMA基座开源之后,也因其出色的性能,迅速吸引了大量开发者。
他们在其基础上开发了各种ChatGPT开源替代品,并且以极低的训练成本屡次达到匹敌GPT-3.5的性能,极大激发了开源模型的创新活力。
未来大模型生态闭源与开源并存,已是行业共识。
凭借闭源路线的GPT、PaLM 2以及开源路线的LLaMA,美国在大模型领域已经构建起了完整的生态。
尽管中文世界不乏优秀的开发者、出色的创新能力和广泛的应用场景,但由于缺少高性能和高定制性的开源基座模型,在大语言模型领域的相关研究和应用上仍存在较大的挑战。
中国急需优质开源可商用大模型补齐相关领域的空白,与开发者和企业共同推动中国人工智能应用的创新生态发展。
开启中文开源大模型商业化时代
作为同级最好的开源可商用中英文预训练语言模型,Baichuan-13B-Base不仅对学术研究完全开放,所有开发者均可通过邮件向百川智能申请授权,在获得官方商用许可后即可免费商用。
并且,为了尽可能降低模型的使用门槛,百川智能同时开源了Baichuan-13B-Chat的INT8和INT4两个量化版本,在近乎无损的情况下可以很方便的将模型部署在如3090等消费级显卡上。
本次百川智能发布的Baichuan-13B中英文大语言模型,凭借百亿参数量已经展现出可以媲美千亿模型的能力,大大降低企业部署和调试的使用成本,让中国开源大模型商业化进入真正可用阶段。
Baichuan-13B的开源,实现了国内开源大模型对美国大模型开源领域的追赶,改变了此前国内在相关领域一直落后的局面。
同时,其开源模型的代码完全公开,所有人都可以随时查看,算法透明,不仅有利于研究人员深入探索和研究模型原理,并且有利于建立和深化公众对大模型的信任,可以说Baichuan-13B不仅是百川大模型之路上的又一里程碑,也是中国大模型快速迭代的重要标志。
百川智能创始人王小川表示,「Baichuan-13B是百川智能为科技强国送上的一份礼物,我们期待国内大模型行业以及垂直领域能够在此基础上开发出更多优秀产品及行业应用,让技术在真实、丰富的应用场景中快速迭代创新,我们愿与众多企业、开发者一道为国内开源社区的生态繁荣贡献自己的力量。」
新智元专访
– 很多人说,中英文语料的差异,会导致大模型极大的差距,你怎么看?
中英文差异导致模型巨大的差异,在行业中的确对此有普遍的想法,但是并没有相关的证据。这反应了一部人的悲观情绪,我们更需要乐观主义精神和坚定的态度。
说中文模型不行只是一个行业猜测,在我们的7B和13B中,并没有看到这样的结果。
从百川7B开始,证明了使用中英文数据进行训练,本身并不会降低模型的能力,并且对英文能力也有提升。
– ChatGPT已经靠Code Interpreter完成惊人升级,百川大模型是否上线类似功能的计划呢?
Code Interpreter是ChatGPT的重大升级,这是OpenAI未来很重要的一个方向,我们对这个事情是高度关注的。
– 百川智能为何要做开源可商用的大模型,现在达到了怎样的一个水平?
业内人士都认为,在国内大多数领先企业都有能力做到3.5的水平,但是有两个关键点——
1. 怎么从3.5做到4,这是一个超级难题。
2. 如何做出超级应用,大家的共识是通过开源模式百花齐放,我们做的开放,就是对生态本身的填补。
另外,我们也会在迈向4和超级应用这个方向做出自己的探索。
– 业内很多人认为,大模型之战的下一个战场就在应用落地上,百川大模型与清华等高校的合作,具体用例在何处?
清华使用我们的模型之后,在法律上是有长足进步的,在科研上也会有他们的探索。
– 百川大模型是否与人类价值观进行了对齐,对齐后的性能是否会下降?
毋庸置疑,百川模型会和人类价值观进行对齐,而且对齐是多个层面的,不仅在微调阶段,还在之前的预训练阶段。
如果只在微调这个阶段性对齐的话,那模型会有明显的对齐税。因此是需要有统一的这样的一个预训练到微调阶段,甚至到最后强化学习阶段的共同对齐。
总而言之,人类价值观对齐是我们必须做好的。我们认为需要多个环节都做好,并且保持一致性,这样就能降低对齐税。
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: Lgxmw666